Hypertable vs. HBase Performance Evaluation II
Table of Contents
Introduction
We conducted an updated Hypertable vs. HBase performance evaluation, comparing the performance of Hypertable version 0.9.5.5 with that of HBase 0.90.4 (with Zookeeper 3.3.4). We attempted to make the test as apples-to-apples as possible and tuned both systems for maximum performance.
The test was modeled after the one described in Section 7 of the Bigtable paper, with the following changes:
- The systems alternately ran on top of the same fixed, sixteen-node HDFS 0.20.2 (CDH3u2) instance.
- The Tablet Server equivalents (RangeServer & RegionServer) were configured to use all available RAM.
- A Random Read test that followed a Zipfian distribution was added to more closely model realistic workload.
- For the random insert and sequential scan tests, we included results for different value sizes ranging from 10KB down to 10 bytes.
The test was run on a total of sixteen machines connected together with Gigabit Ethernet. The machines had the following configuration:
OS: CentOS 6.1 CPU: 2X AMD C32 Six Core Model 4170 HE 2.1Ghz RAM: 24GB 1333 MHz DDR3 disk: 4X 2TB SATA Western Digital RE4-GP WD2002FYPS
The HDFS NameNode and Hypertable and HBase master was run on test01. The DataNodes were run on test04..test15 and the RangeServer and RegionServers were run on the same set of machines and were configured to use all available RAM. Three Zookeeper and Hyperspace replicas were run on test01..test03.
As described in section 7 of the Bigtable paper, the test consisted of a central dispatcher (run on test00), and some number of test client processes (running on test00…test03). For complete details on how to setup and run this test, see Test Setup.
The Java client API was used for both systems.
Schema
A single table was used for this test. It was configured to keep all versions, use Snappy compression, and create Bloom filters using the row key. These configurations are default for Hypertable, but needed to be explicitly set in HBase. The following statements were used to create the table in each system.
hypertable:
create table perftest ( column );
hbase:
create 'perftest', { NAME => 'column', VERSIONS => 1000000, COMPRESSION => 'SNAPPY', BLOOMFILTER => 'row' }
Notes on HBase Tuning
We used the native Snappy compression libraries that ship with CDH3. For the JVM heap size, we settled on 14GB after much trial and error. While some of the tests ran with a larger heap size, the resulting performance was not any better.
Unfortunately, we were unable to get complete HBase results for some of the tests due to the RegionServers consistently crashing with Concurrent mode failure exceptions. This error occurs due to the application generating garbage at a rate that is too fast for the Java garbage collector (see Avoiding Full GCs in HBase with MemStore-Local Allocation Buffers for more details on this error).
We spent a considerable amount of time tuning HBase. We consulted the many available resources, including the following:
- Apache HBase book
- O'Reilly book HBase the Definitive Guide - Chapter 11. Performance Tuning
- HBase Wiki - Performance Tuning
- Cloudera's three part series on avoiding full GCs in HBase
- HBase mailing list archives
- Direct assistance from HBase committers on the HBase mailing list
Unfortunately for the 100-byte and 10-byte random write tests we were unable to get results due to the RegionServers consistently crashing with Concurrent mode failure exceptions. We ran close to twenty tests, varying the heapsize, the CMSInitiatingOccupancyFraction, the hbase.hstore.compactionThreshold property, hbase.regionserver.global.memstore.upper/lowerLimit, and the number of test clients, but were unable to get the tests to complete successfully. It appears that the amount of background maintenance activity that accumulates during these tests eventually builds to a point that overwhelms the garbage collector.
Random Write
In this test we wrote 5TB of data into both Hypertable and HBase in four different runs, using value sizes 10000, 1000, 100, and 10. The key was fixed at 20 bytes and was formatted as a zero-padded, random integer in the range, [0..number_of_keys_submitted*10) The data for the value was a random snippet taken from a 200MB sample of the english Wikipedia XML pages.
Configuration
The following non-default configuration properties were used for this test:
Hypertable
hypertable.cfg:
Hypertable.RangeServer.Range.SplitSize=1GB
HBase
hbase-site.xml:
| Property | Value |
|---|---|
hbase.regionserver.handler.count |
50 |
hbase.cluster.distributed |
true |
hfile.block.cache.size |
0 |
hbase.hregion.max.filesize |
2147483648 |
hbase.regionserver.global.memstore.upperLimit |
0.79 |
hbase.regionserver.global.memstore.lowerLimit |
0.70 |
hbase.hregion.majorcompaction |
0 |
hbase.hstore.compactionThreshold |
6 |
hbase.rpc.timeout |
0 |
zookeeper.session.timeout |
1209600000 |
hbase-env.sh:
export HBASE_REGIONSERVER_OPT="-Xmx14g -Xms14g -Xmn128m -XX:+UseParNewGC \
-XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 \
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps \
-Xloggc:$HBASE_HOME/logs/gc-$(hostname)-hbase.log"
export HBASE_LIBRARY_PATH=/usr/lib/hadoop/lib/native/Linux-amd64-64
The results of this test are summarized in the following chart:
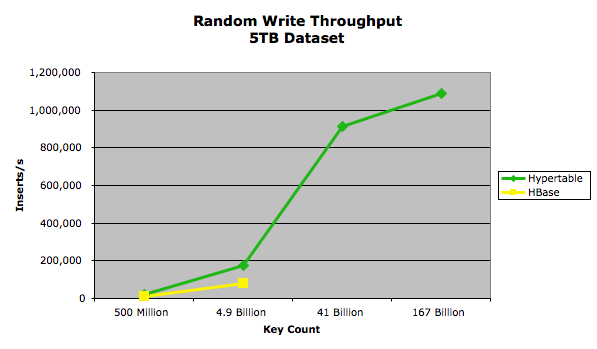
The exact performance measurements are provided in the following table:
| Value Size | Key Count |
Hypertable Throughput MB/s |
HBase Throughput MB/s |
|---|---|---|---|
| 10,000 | 500,041,347 | 188 | 93.5 |
| 1,000 | 4,912,173,058 | 183 | 84 |
| 100 | 41,753,471,955 | 113 | ? |
| 10 | 167,013,888,782 | 34 | ? |
* No results were obtained for HBase 41 billion and 166 billion key tests due to the Concurrent mode failure exception
Scan
In this test we scanned the entire dataset loaded in each of the four Random Write tests. The configuration for each system was the same as the one used in the Random Write tests. The results of this test are summarized in the following chart:
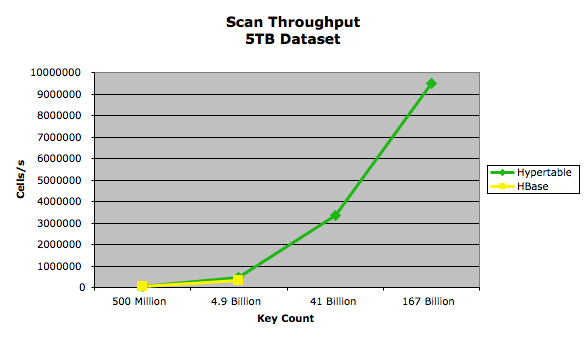
The exact performance measurements are provided in the following table:
| Value Size | Keys Submitted |
Hypertable Keys Returned |
HBase Keys Returned |
Hypertable Throughput MB/s |
HBase Throughput MB/s |
|---|---|---|---|---|---|
| 10,000 | 500,041,347 | 500,041,347 | 500,026,388 | 478 | 397 |
| 1,000 | 4,912,173,058 | 4,912,173,058 | 4,912,184,933 | 469 | 371 |
| 100 | 41,753,471,955 | 41,753,471,955 | * | 413 | * |
| 10 | 167,013,888,782 | 167,013,888,782 | * | 292 | * |
* No results were obtained for HBase 41 billion and 167 billion key tests due to the Concurrent mode failure exception
The four client machines each were configured to use a single 1-gigabit network interface, which capped the aggregate throughput at the theoretical maximum of 500 MB/s. We expect that the results would be better without this limitation.
Random Read
In this test we measured the query throughput for a set of random read requests. Two tests were run on each system, one following a Zipfian distribution (modeling realistic workload) and another that followed a uniform distribution. Each inserted key/value pair had a fixed key size of 20 bytes and a fixed value size of 1KB, and the value data was a random sample from the English XML export of Wikipedia. We ran two tests on each system, one in which we loaded the database with 5TB and another in which we loaded 0.5TB. This allowed us to measure the performance of each system under both high and low RAM-to-disk ratios. In the 5TB test, 4,901,960,784 key/value pairs were loaded and in the 0.5TB test 490,196,078 keys were loaded. The keys were ASCII integers in the range [0..total_keys) so that every query resulted in a match, returning exactly one key/value pair. Each test client machine ran 128 test client processes for a total of 512, and each test client issued queries in series so there was a maximum of 512 queries outstanding at any given time. A total of 100 million queries were issued for each test.
Zipfian
In this test, the set of keys queried followed a Zipfian distribution. We used an exponent value of 0.8, which means that 20% of the keys appeared 80% of the time.
Configuration
The following non-default configuration was used for this test.
Hypertable (hypertable.cfg):
Hypertable.RangeServer.Range.SplitSize=1GB Hypertable.RangeServer.QueryCache.MaxMemory=2GB
HBase (hbase-site.xml):
| Property | Value |
|---|---|
HBase.regionserver.handler.count |
50 |
HBase.cluster.distributed |
true |
HBase.hregion.max.filesize |
2,147,483,648 |
HBase.hregion.majorcompaction |
0 |
HBase.hstore.compactionThreshold |
6 |
HBase.rpc.timeout |
0 |
zookeeper.session.timeout |
1209600000 |
HBase (hbase-env.sh):
export HBASE_REGIONSERVER_OPT="-Xmx14g -Xms14g -Xmn128m -XX:+UseParNewGC \
-XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 \
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps \
-Xloggc:$HBASE_HOME/logs/gc-$(hostname)-HBase.log"
export HBASE_LIBRARY_PATH=/usr/lib/hadoop/lib/native/Linux-amd64-64
The results of this test are summarized in the following chart.
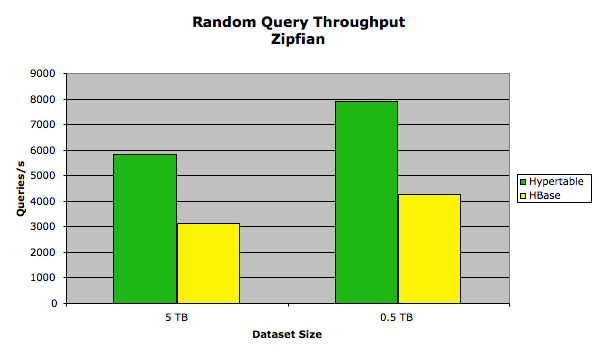
The exact performance measurements are provided in the following table:
|
Dataset Size |
Hypertable Queries/s |
HBase Queries/s |
Hypertable Latency (ms) |
HBase Latency (ms) |
|---|---|---|---|---|
| 0.5 TB | 7901.02 | 4254.81 | 64.764 | 120.299 |
| 5 TB | 5842.37 | 3113.95 | 87.532 | 164.366 |
Uniform
In this test, the set of keys queried followed a uniform distribution.
Configuration
The following non-default configuration was used for this test.
Hypertable (hypertable.cfg):
Hypertable.RangeServer.Range.SplitSize=1GB
HBase:
Same configuration as the Zipfian test.
The following chart summarizes the results.
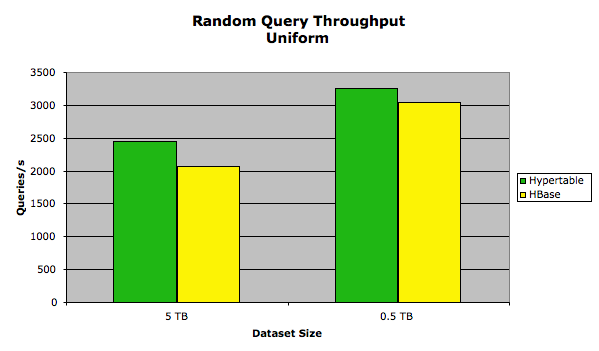
The exact performance measurements are provided in the following table.
|
Dataset Size |
Hypertable Queries/s |
HBase Queries/s |
Hypertable Latency (ms) |
HBase Latency (ms) |
|---|---|---|---|---|
| 0.5 TB | 3256.42 | 2969.52 | 157.221 | 172.351 |
| 5 TB | 2450.01 | 2066.52 | 208.972 | 247.680 |
Conclusion
As can be seen in the results, Hypertable significantly outperformed HBase in all tests except for the random read uniform test. The lack of data points for the HBase 41 billion and 167 billion key write tests were due to the HBase RegionServers throwing Concurrent mode failure exceptions. This failure occurs, regardless of the configuration, when the RegionServer generates garbage at a rate that overwhelms the Java garbage collector. We believe that while it is possible to construct a garbage collection scheme to overcome these problems, it would come at a heavy cost in runtime performance. The paper Quantifying the Performance of Garbage Collection vs. Explicit Memory Management, by Matthew Hertz and Emery D. Berger, presented at OOPSLA 2005, provides research that supports this belief. The discrepancy in the random read Zipfian tests is due to the benefit provided to Hypertable by its query cache, a subsystem that is not present in HBase. A query cache could be implemented in HBase, but it is a subsystem that generates a lot of garbage (in the write path), so we believe that while it may improve performance for some workloads, it will have a detrimental impact on others, especially write-heavy and mixed workloads with large cell counts. One interesting thing to note is that when we increased the size of the block cache in both systems it had a detrimental effect on performance. We believe that this is due to the fact that the systems had plenty of spare CPU capacity to keep up with the decompression demand. By eliminating the block cache, which stores uncompressed blocks, and relying on the operating system file cache, which stores compressed blocks, better performance was achieved because more of the data set could fit in memory. And finally, the HBase performance was close to that of Hypertable in the random read uniform tests due to the bottleneck being disk I/O and the minimal amount of garbage generated during the test.
