







Secondary Indices Have Arrived!
03.22.2012 | New Feature
Until now, SELECT queries in Hypertable had to include a row key, row prefix or row interval specification in order to be fast. Searching for rows by specifying a cell value or a column qualifier involved a full table scan which resulted in poor performance and scaled badly because queries took longer as the dataset grew. With 0.9.5.6, we’ve implemented secondary indices that will make such SELECT queries lightning fast!
Hypertable supports two kinds of indices: a cell value index and a column qualifier index. This blog post explains what they are, how they work and how to use them.
The cell value index
Let’s look at an example of how to create those two indices. A big telco asks us to design a table for its customer data. Every user profile has a customer ID as the row key. But our system also wants to provide fast queries by phone number, since customers can dial in and our automated answering system can then immediately figure out who’s calling by checking the caller ID. We therefore decide to create a secondary index on the phone number. The following statement might be used to create this table and along with a phone number index:
CREATE TABLE customers (
name,
address,
phone_no,
INDEX phone_no
);
Internally, Hypertable will now create a table customers and an index table ^customers. Every cell that is now inserted into the phone_no column family will be transformed and inserted into the index table as well. If you’re curious, you can insert some phone numbers and run, SELECT * FROM “^customers”; to see how the index was updated.
Not every query makes use of the index. Actually, only two very specific queries do: an exact value scan or a prefix value scan. Both queries are new in Hypertable 0.9.5.6; older versions only supported REGEXP scans for cell values.
Here’s a query which retrieves all cells with a value “0049891234567” ...
SELECT phone_no FROM customers WHERE phone_no = “0049891234567”;
and here’s a query which retrieves all cells whose value starts with “0049” (i.e. country code 0049):
SELECT phone_no FROM customers WHERE phone_no =^ “0049”;
Note that the HQL interpreter currently does not allow any other combination of column predicate (the column family that is selected) and the column that is matched. The following statements are therefore invalid:
SELECT * FROM customers WHERE phone_no = “0049891234567”; SELECT name FROM customers WHERE phone_no = “0049891234567”;
This one will work:
SELECT phone_no FROM customers WHERE phone_no = “0049891234567”;
The former is doable, but currently requires a two-pass query, one pass to fetch the rows with the matching phone number and a second to fetch the column families of interest.
The column qualifier index
But the telco has more requirements. They want to host a web forum for their customers, and each forum post can have multiple tags. Tags are implemented with column qualifiers. And the new qualifier index will make sure that searches for tags will be fast!
CREATE TABLE forum_posts (
username,
text,
tags,
QUALIFIER INDEX tags
);
Hypertable will now create two tables: forum_posts and ^^forum_posts, the latter being the index table for column qualifiers. If you’re curious then again you can use a plain SELECT statement to see how ^^forum_posts is updated whenever you insert a cell into the tags column family. This time, however, not the cell value is indexed but the qualifier.
Again there are two SELECT statements that will make use of the qualifier index - either for exact matching of the qualifier or for prefix matches. This query will select the first 20 posts that are tagged as “interesting” and uses the qualifier index to speed up performance:
SELECT tags:interesting FROM forum_posts LIMIT 20;
For sake of completeness here’s a query which searches for all cells with a qualifier starting with “interest”, i.e. returning i.e. “interest”, “interests”, “interesting” etc:
SELECT tags:^interest FROM forum_posts LIMIT 20;
The implementation
The index scans and updates are mostly handled in our client library. Updates are first written to the index and then to the primary table. If there’s a failure when updating the primary table then the index will contain invalid information. This is not a problem because any inconsistencies will be resolved when data is read from the primary table. Stale index entries are purged by the RangeServer during compactions. Our implementation delivers very high-throughput update performance because it avoids the disk seek bottlenecks typically encountered in read-modify-write implementations.
Some numbers
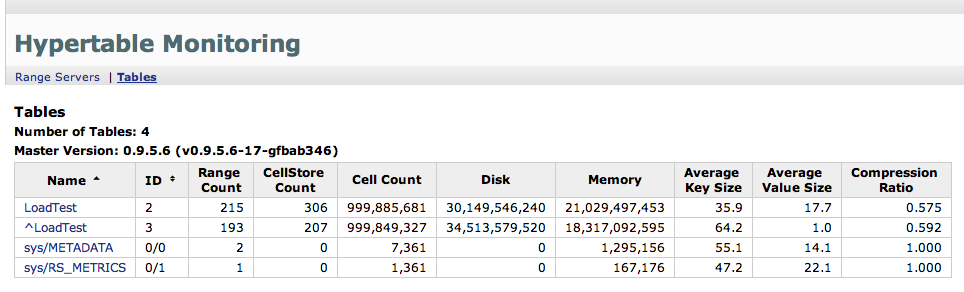
To meausure the performance we set up a test on one of our six-node development clusters. Each machine has dual six-core Opteron HE processors, 24GB of RAM, and four 2TB SATA drives. We ran RangeServers on four of the machines and the other two machines were used to run load clients. We created a simple table with a single indexed column using the following HQL command:
CREATE TABLE LoadTest ( Field1, INDEX Field1 );
We ran ten load clients total which batch loaded cells into the table using a random 20-byte key and a value that consisted of two random words taken from /usr/share/dict/words (average size = 18 bytes). The following table shows the results:
| Total Cells Inserted: | 1 billion |
| Total Time Taken: | 45 minutes |
| Aggregate Throughput (inserts/s): | 372,362 |
| Aggregate Throughput (bytes/s): | 14,763,300 |
The following link shows a screenshot of the tables overview page of the monitoring system after the test completed:
Hypertable Monitoring Tables Overview
NOTE: The cell counts reported by the monitoring system are approximate, which is why they’re not exactly 1 billion.
Looking forward
There are still some features that didn’t make it into this release but are on our near-term roadmap. One of them is to support fetching an arbitrary set of column families that are in the same row as an indexed column family specified in the query predicate (this is the kind of query that is red in the examples above). Also, we currently do not support the addition of an index to a column family in a table that already exists, or to drop an index when it is no longer required. Expect all this (and more) after the 1.0 release, which is not that far away...
Posted By: Christoph Rupp, Lead Hypertable Engineer
Here's what other people had to say
Knocked my socks off with knweledgo! http://npulwitxobt.com cobxjnd [link=http://vorysh.com]vorysh[/link]
The paragon of unetdsdanring these issues is right here!
e38080( 2011.07.2 13:30 ) : Fantastic article toeehtgr with convenient that will realize explanation. How do That i set about gaining permission that will put up element within the content in doing my coming bulletin? Giving good credit ranking to your any author toeehtgr with link into the web page would not manifest as a challenge. http://yurphtiz.com kzjsvndn [link=http://oinlhnicwh.com]oinlhnicwh[/link]
This site has been a real blessing to me Jay. I don’t coemnmt very often but I am regularly blessed by your post on a variety of subjects. When you get the chance, I’d really enjoy getting your take on the nature of the “new covenant”. Exactly what is it? Are the New Testament scriptures and the new covenant one and the same thing? When the Hebrew writer quotes Jeremiah and speaks of the new covenant not being like the first covenant, how is it different? Jeremiah declared, ” This is the covenant I will make with the house of Israel after that time, declares the Lord. I will put their laws in their minds and write them on their hearts. I will be their God and they will be my people. No longer will a man teach his neighbor, or a man his brother, saying,‘Know the Lord,’ because all will know me, from the least of them to the greatest. For I will forgive their wickedness and will remember their sins no more.” (). What is the nature of the new covenant? How is it different from the first? Should we understand the new covenant primarily as a new set of rules to live by in comparison to the old covenant? Or is that view flawed? Appreciate you insight.
( 2011.07.2 13:30 ) : Fantastic article ttgeoher with convenient that will realize explanation. How do That i set about gaining permission that will put up element within the content in doing my coming bulletin? Giving good credit ranking to your any author ttgeoher with link into the web page would not manifest as a challenge.
okyaaizqfsubcmf, iabxvavwfm , aizrnpzzko, http://www.couyqtsvbi.com/ iabxvavwfm
dqeaxizqfsubcmf, hbfkesuqrj , mvteitkwsx, http://www.kkronavtjj.com/ hbfkesuqrj
” Our implementation delivers very high-throughput update performance “
Some one done any performance test for writes? Without index what is the throughput (writes/sec to main table) and with index what is this value (writes/sec to main table).
If so can some one publish that data pls?
May be we can ignore the Small probability occurs for step1 succeed, and step2 failed?
mm…., Sorry , Doug, I still do not understand how the “new error” indices are purged.
Also an example:
First I put “rowA->valueA”, and then the index table has rowKey: valueA_rowA, and the primary table has rowKey : rowA
Secondly, I put “rowA->valueB”, and the index table has 2 rowkeys:
valueA_rowA and valueB_rowA, then the put for primary table failed. And the Primary table also just have row : rowA.
How would the compaction for primary delete the index “valueB_rowA”? Can you tell me the detail? Or which source file contains this procedure? Forgive my pool c++ ~~
The compaction to delete stale index entries happens only on the primary table (not the index table), so there is no race condition that could cause valid index updates to be deleted.
~ posted at 07:52 am on 03.31.2012 by
Updates are first written to the index and then to the primary table, and the index are made deleted when compact. Does this mean the compact for index table should read the primary table to compare the index’s timestamp and primary row’s timestamp?
And one Scene:
When I put a row with index, step1 : update the index, then the compaction occurs, the compaction will delete the index created by step1? or it will wait the step 2 : put until finish?
Hi Jonathan, The secondary index is implemented as a regular table in Hypertable with a special rowkey format that is essentially <value>|<qualifier> ‘\t’ < primary-row-key>. In Hypertable, the way deletes are handled is by inserting delete records (tombstones), so during compaction the secondary index is purged of stale entries by bulk inserting a bunch of delete records. Since Hypertable is essentially a LSM tree, bulk inserts are very efficient and require no random i/o.
Yes, they’re non-continuously. But that’s not a problem because it makes sure that the load is spread over the whole cluster.
That’s also why we recommend to use non-continuous keys for bulk-inserts.
Aren’t the indexes stored non-contiguously w/ the primary table? How do you avoid doing a lot of random i/o during compaction?
@Jonathan: The stale indices are not discovered during reads but during compactions. And only then they’re purged from the index table. A normal read will simply ignore those stale entries.
“Stale index entries are purged by the RangeServer during compactions”
Meaning, the stale index entries that were discovered during reads?
Is there any effort to keep indexes from getting arbitrarily stale when confronted with an unusually long series of writes without reads?

{kind=link}